String Fingerprints
Strings. This is the data type that Amazon Redshift reports account for more than 50% of its fleet data (van Renen et al., 2024). As the amount of string data to scan increases, queries become slower, therefore query engines require fast pre-filters to accelerate them.
However, when it comes to query execution on string-valued columns, systems provide only limited solutions. To see an example, note that modern file formats such as Parquet, while they have the celebrated min/max zonemaps to skip non-matching row groups, they lack zonemaps to skip infix LIKE predicates such as WHERE comment LIKE '%fox%'. Indeed, min/max zonemaps can only help in the case of prefix LIKE predicates, as in (Zimmerer et al., 2025). Other zonemap structures, like bloom filters, as in Postgres or Parquet, also don’t help here, as we’d have to insert all possible substrings of a row group’s strings.
This is where string fingerprints (Stoian et al., 2025) come into play. In this blog post, we only outline how they can help to skip non-matching rows. Extending them to row groups is an (exciting) work in progress.
String Fingerprints
The original idea of string fingerprints came to us last year on a train trip from Nuremberg to Munich. We wanted to have a way to skip as many non-matching tuples as possible for a LIKE predicate. Our first idea was pretty simple: If a string does not contain all letters of a pattern, then it can’t contain it.
Now, you don’t want to store a bitmap for all possible letters – this would be too much overhead. Instead, we can cluster the letters into some bins, and mark the bins that have the letters contained in the to-be-fingerprinted string. Let’s do our favorite example – how to fingerprint the string “nutella”, given the following partitioning of the alphabet:

You can see that the blue letters (n, t, e) are mapped to the 3rd bin, while the brown letters are mapped to the 1st bin. Therefore, the fingerprint reads: 1010.
Let’s now fingerprint more strings. To this end, consider the column spelling of the following table and its fingerprints in str_fp. The first row is “nutella” (we already did it above). Now we come to “unt”, which gets the same fingerprint. Finally, “thon” is mapped to 0111.

Assume now you’re performing a filter WHERE spelling LIKE '%utn%'. We simply have to fingerprint the pattern, in this case 1010, and check which table fingerprints don’t contain it, i.e., there exists at least one bin where the pattern has a 1 while the considered row fingerprint does not. We see that 1010 is not contained in 0111 – there’s a mismatch already at the first bin. This means, the LIKE predicate would anyway evaluate to false for this row, so we can skip it.
Optimizing the Partition
Whenever I present string fingerprints, the first question I get is: “But how do you optimize the partition?”. If you have no information about your query workload, taking a random mapping is enough (we just chose a round-robin placement; basically each letter is mapped to ASCII(letter) % 4). But let’s say you have the workload; say your customer provides you with that. In that case, you can do better.
At UTN, we strive to be interdisciplinary. As the last slide of my PhD proposal deck, I pitched the idea of having string zonemaps to Johannes Thürauf, our professor for Discrete Optimization. He liked it, so we decided, given his expertise, that it’d be a promising idea to optimize the partition. Two weeks later, we had the mixed-integer program (MIP) and could then test it. The idea is to optimize the false positive rate of your string fingerprints using the column data and the query workload. You can read more about the MIP in the 2nd section of our paper.
Community Adoption
I was very happy to see that string fingerprints got adopted very quickly. For instance, SqueezeCache (coming from its parent project, LiquidCache) uses 32-bit string fingerprints in their cache data structure to skip scanning the mapped Parquet rows.
Our code, along with Johannes’ MIP implementation, are open source on our GitHub page: Instance-Optimized String Fingerprints (AIDB @VLDB’25).
References
-
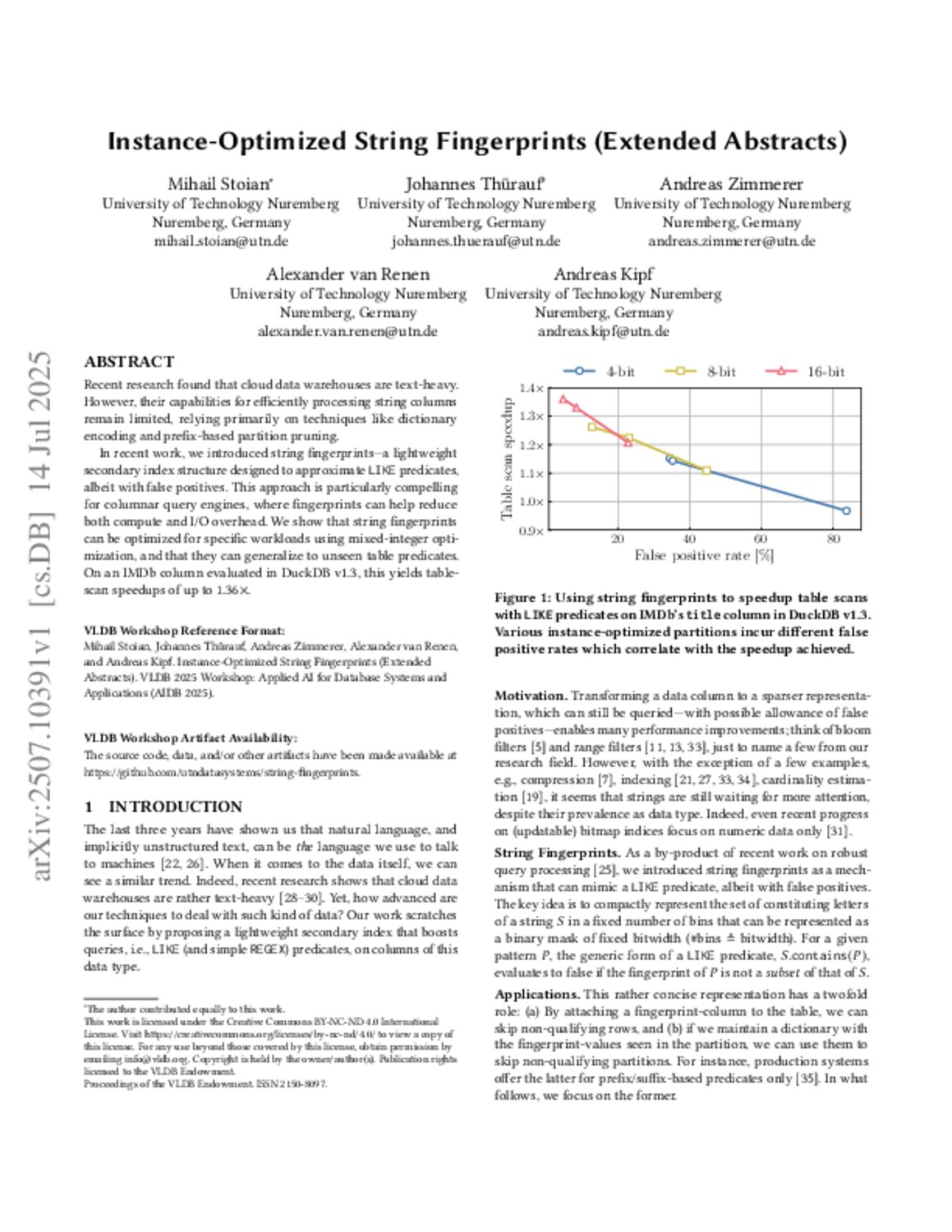 VLDB 2025 Workshop: Applied AI for Database Systems and Applications (AIDB 2025), 2025
VLDB 2025 Workshop: Applied AI for Database Systems and Applications (AIDB 2025), 2025
